Making decisions
Lecture 25
December 2, 2025
It’s Giving Tuesday – Give feedback!
Take 2 minutes to fill out the TA evaluation form – link in your email! Due Monday, December 8th.
Nominate a TA for the StatSci TA of the Year award by sending an email to dus@stat.duke.edu with a brief narrative for your nomination.

- Please also fill out the course evaluation (on DukeHub) as well, I’d love to your feedback!
Participate 📱💻
Which of the following is true about confidence intervals?
- They’re for a sample statistic.
- They’re for a population parameter.
- They can be either for both a sample statistic or a population parameter.
- They’re neither for a sample statistic nor a population parameter.

Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
What does each observation on the plot represent?
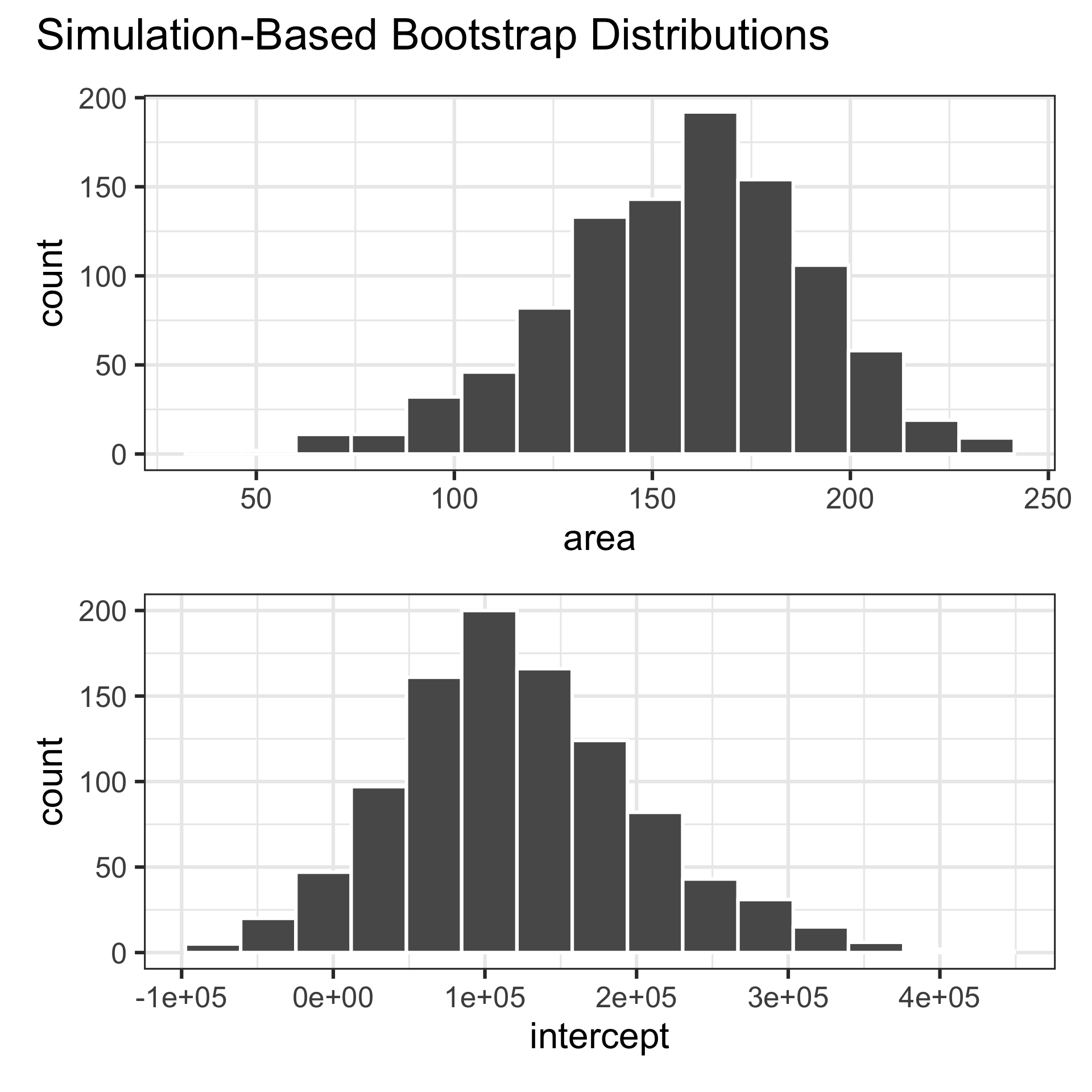
- Resample, with replacement, from the original data
- Do this
reps = 1000times - Calculate the summary statistic of interest in each of these samples
Participate 📱💻
If you want to be very certain (i.e., more confident) that you capture the population parameter, should we use a wider or a narrower interval?
- Wider
- Narrower
- Depends on the situation
Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
Precision vs. accuracy
What drawbacks are associated with using a wider interval?

Margin of error
That quantity (~2 * standard error) is called the margin of error, e.g.,

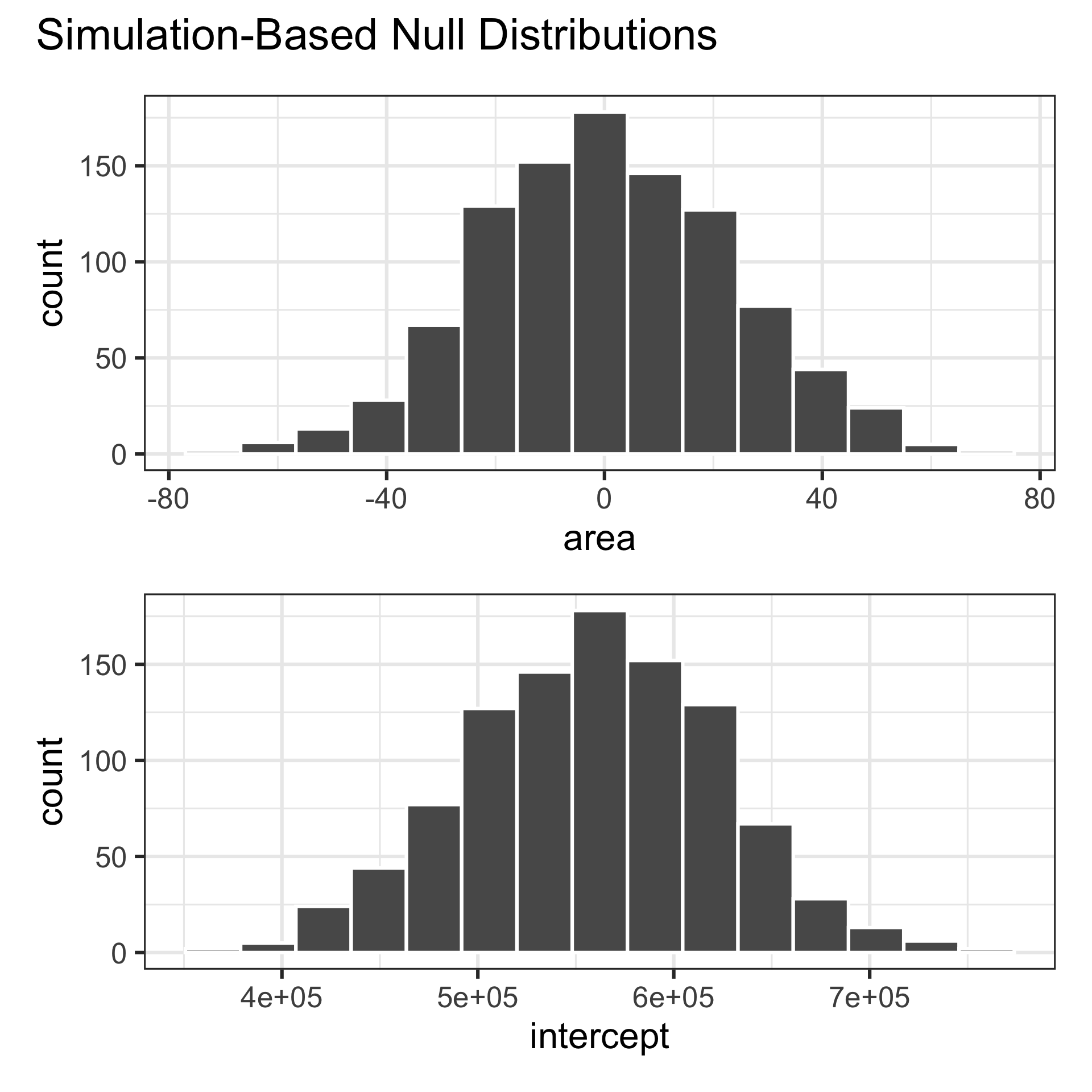
Visualize null distribution