Evaluating models
Lecture 22
November 13, 2025
While you wait: Participate 📱💻
What is sensitivity also known as?
- True positive rate
- True negative rate
- False positive rate
- False negative rate
- Recall

Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
From last class: Participate 📱💻
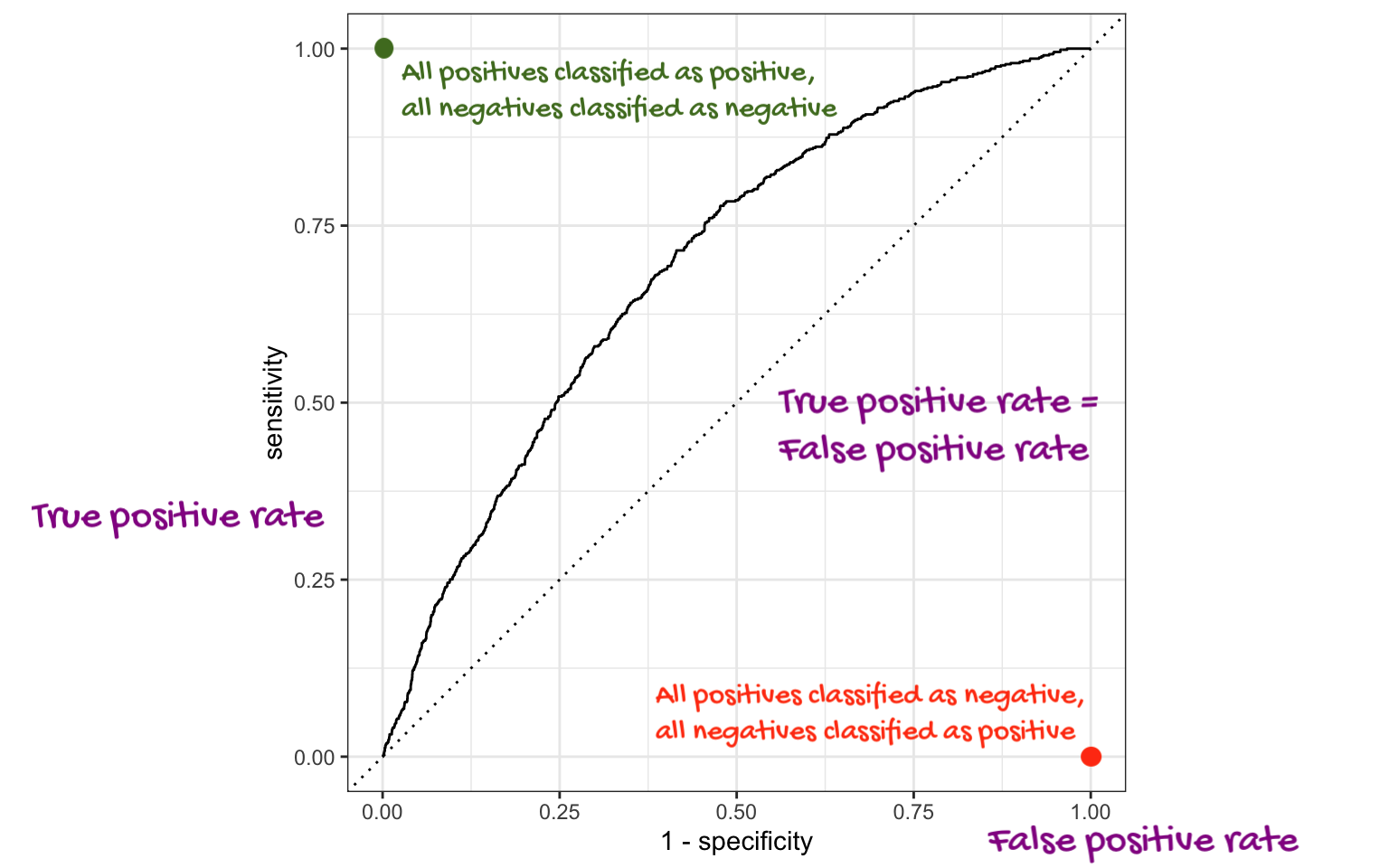
Which of the following best describes the area annotated on the ROC curve?
- Where all positives classified as positive, all negatives classified as negative
- Where true positive rate = false positive rate
- Where all positives classified as negative, all negatives classified as positive
Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
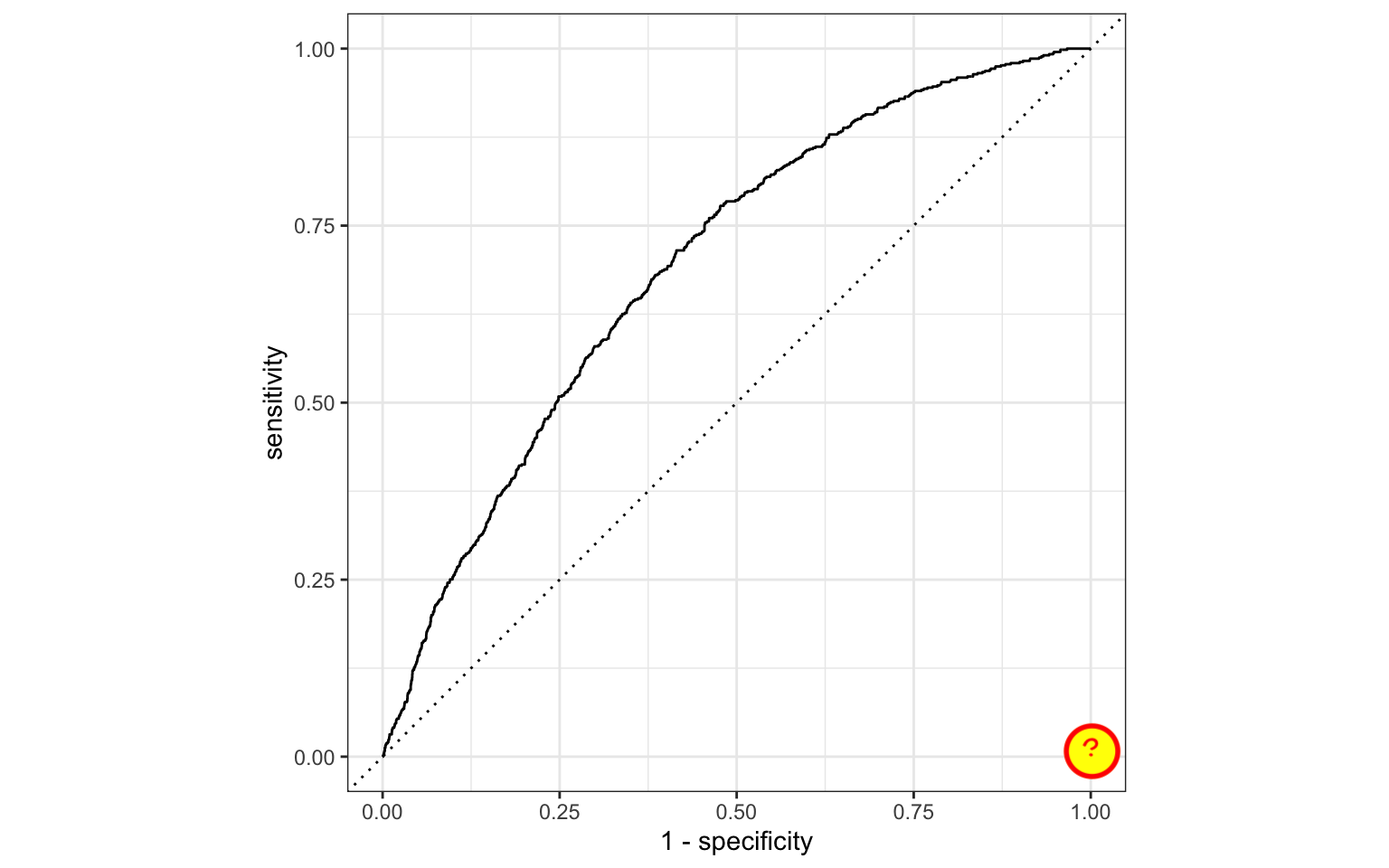
ROC curve
Which corner of the plot indicates the best model performance?