Spending your data
Lecture 21
November 11, 2025
While you wait: Participate 📱💻
Which of the following files should you be updating in your project between now and Thursday’s deadline? Check all that apply.
contract.qmdindex.qmd-
presentation.qmdorpresentation.pdf proposal.qmd-
README.mdin yourdatafolder

Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
Spending your data
For predictive models (used primarily in machine learning), we typically split data into training and test sets:

The training set is used to estimate model parameters.
The test set is used to find an independent assessment of model performance.
Warning
Do not use, or even peek at, the test set during training.
While you wait: Participate 📱💻
Which dataset should we use for the exploration?
- The entire data
chicago_taxi - The training data
chicago_taxi_train - The testing data
chicago_taxi_test
Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
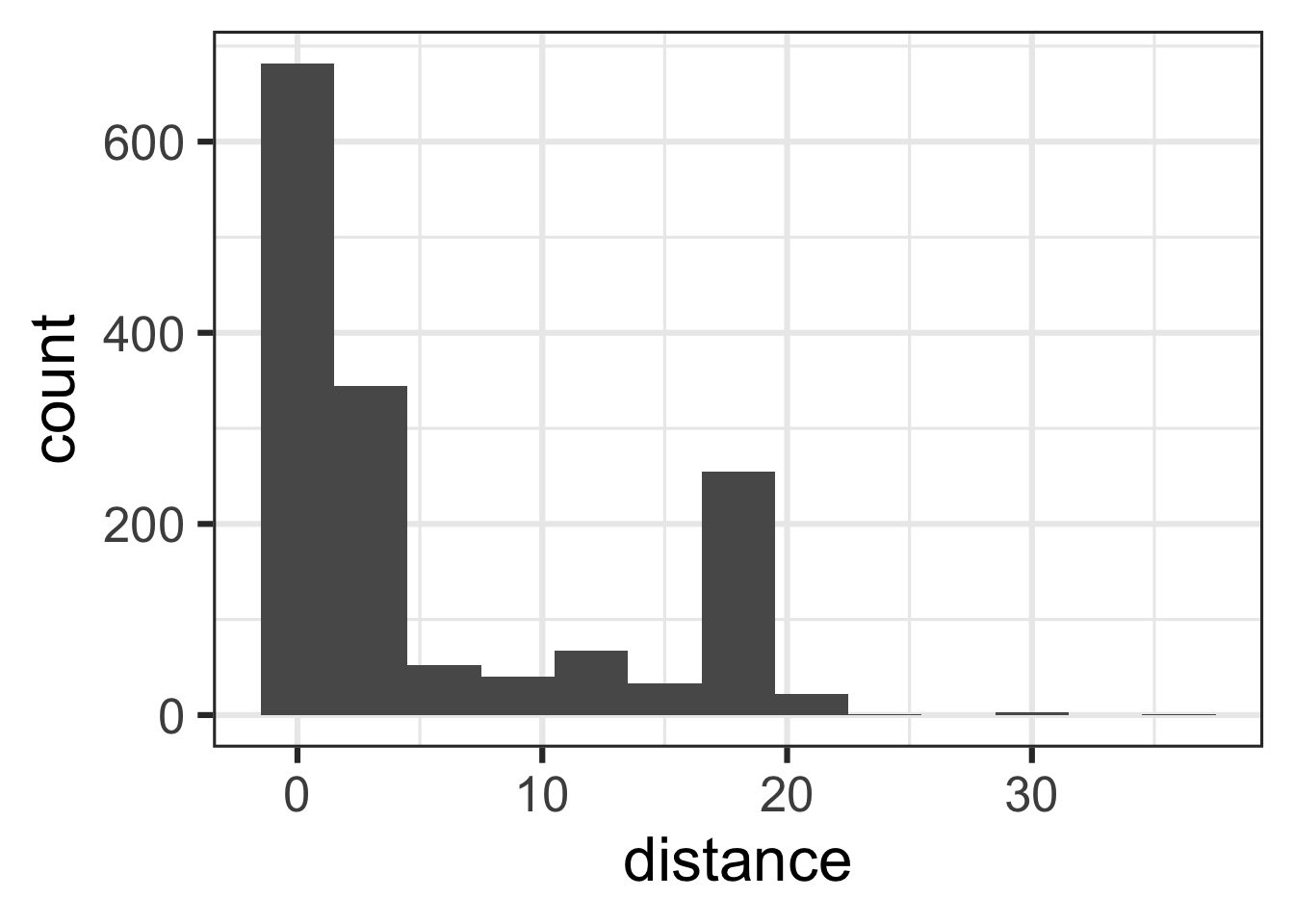
distance
What’s the distribution of distance?
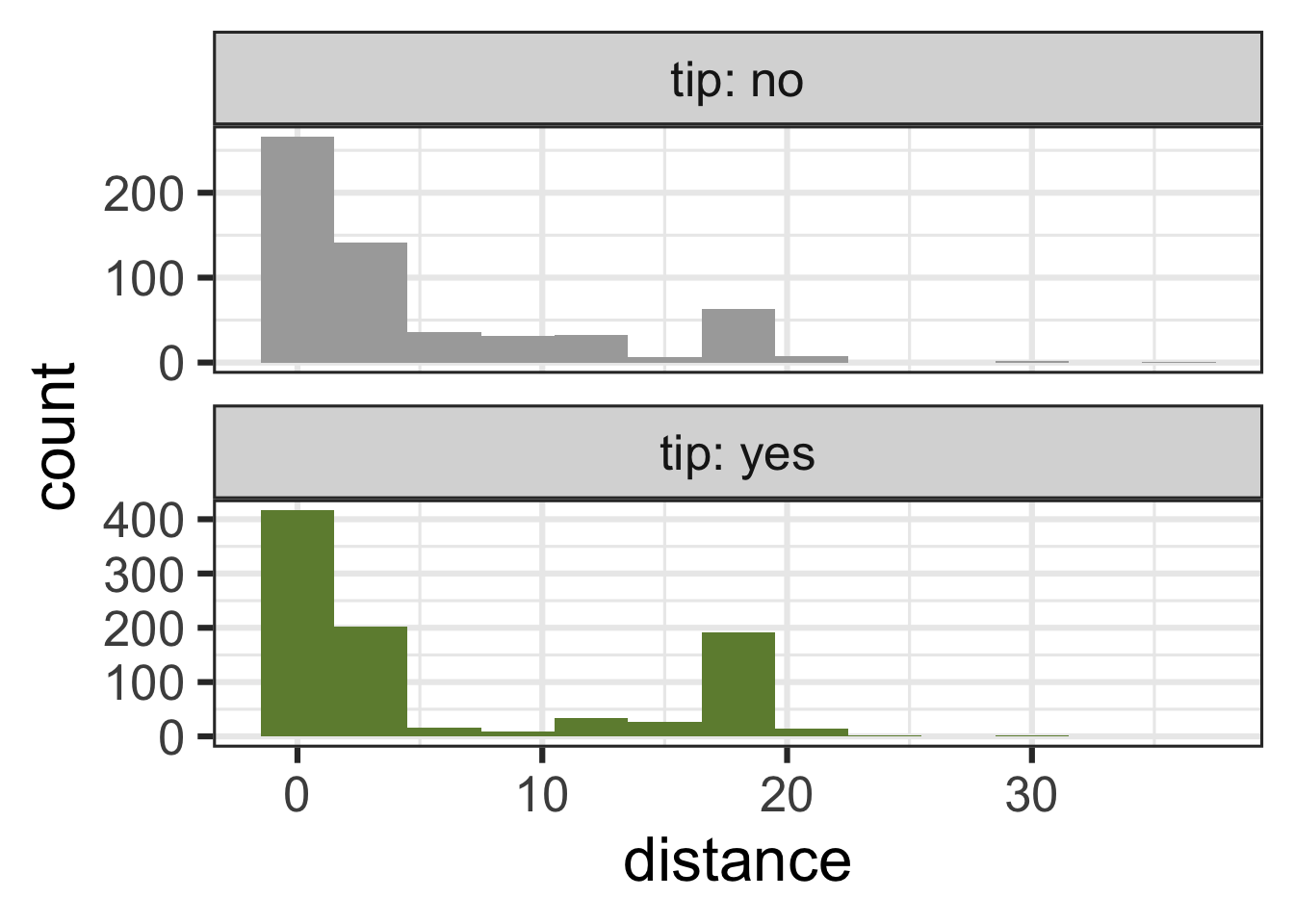
tip and distance
tip and hour
ggplot(chicago_taxi_train, aes(x = hour, fill = tip, group = tip)) +
geom_histogram(binwidth = 1, show.legend = FALSE) +
scale_fill_manual(values = c("yes" = "darkolivegreen4", "no" = "darkgray")) +
scale_x_continuous(breaks = seq(0, 18, by = 6)) +
facet_wrap(~tip, ncol = 1, labeller = label_both, scales = "free_y")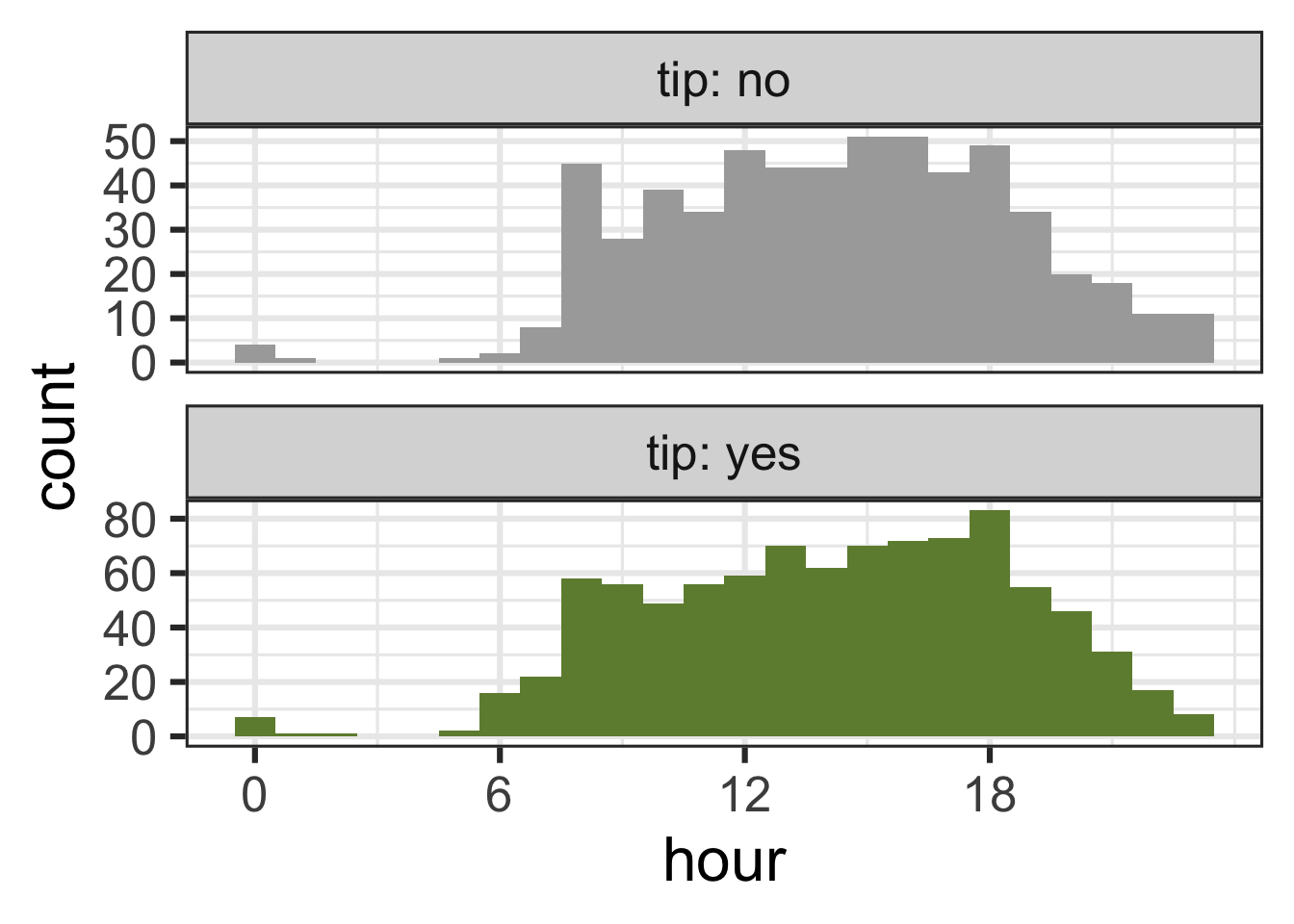
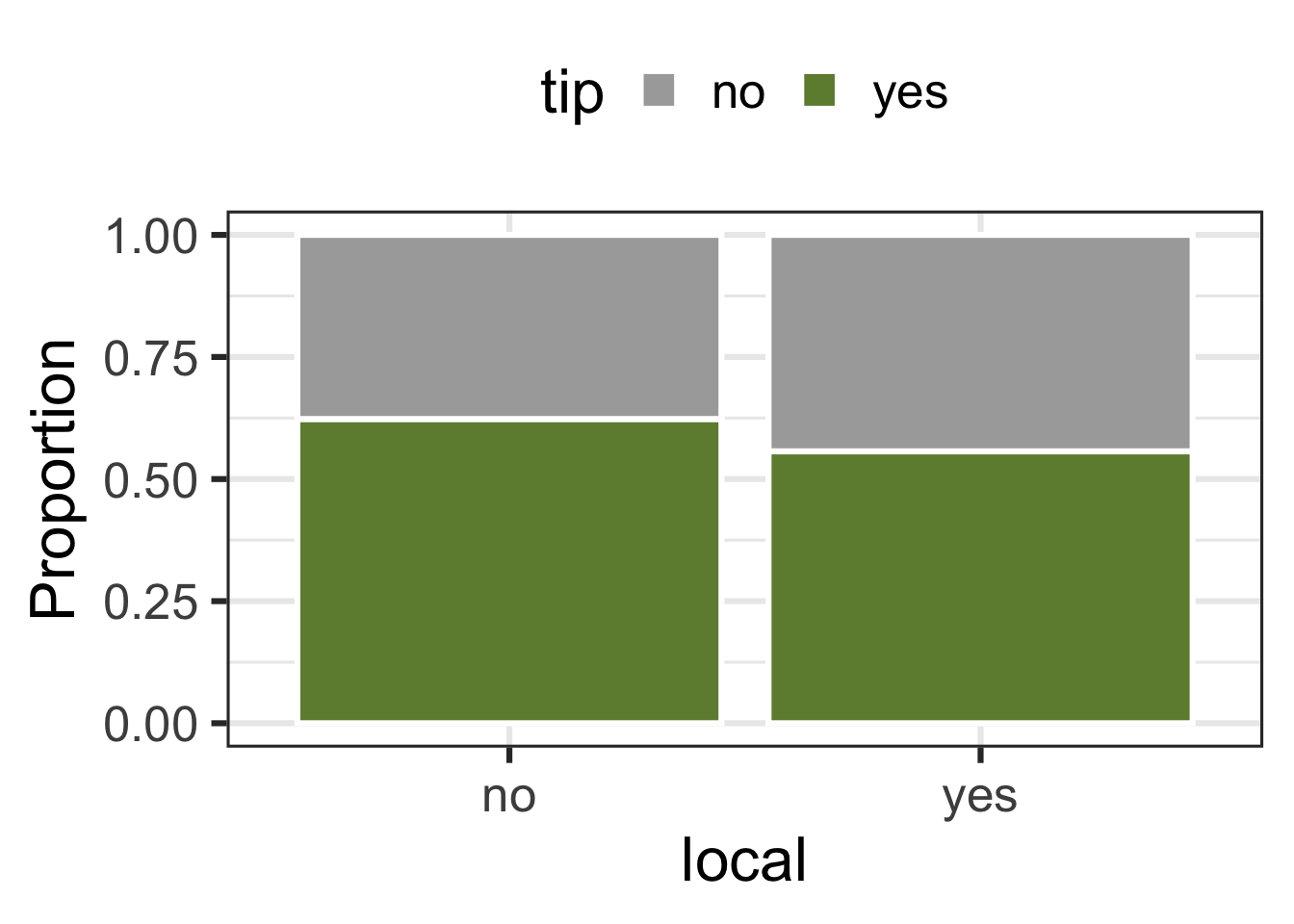
tip and local
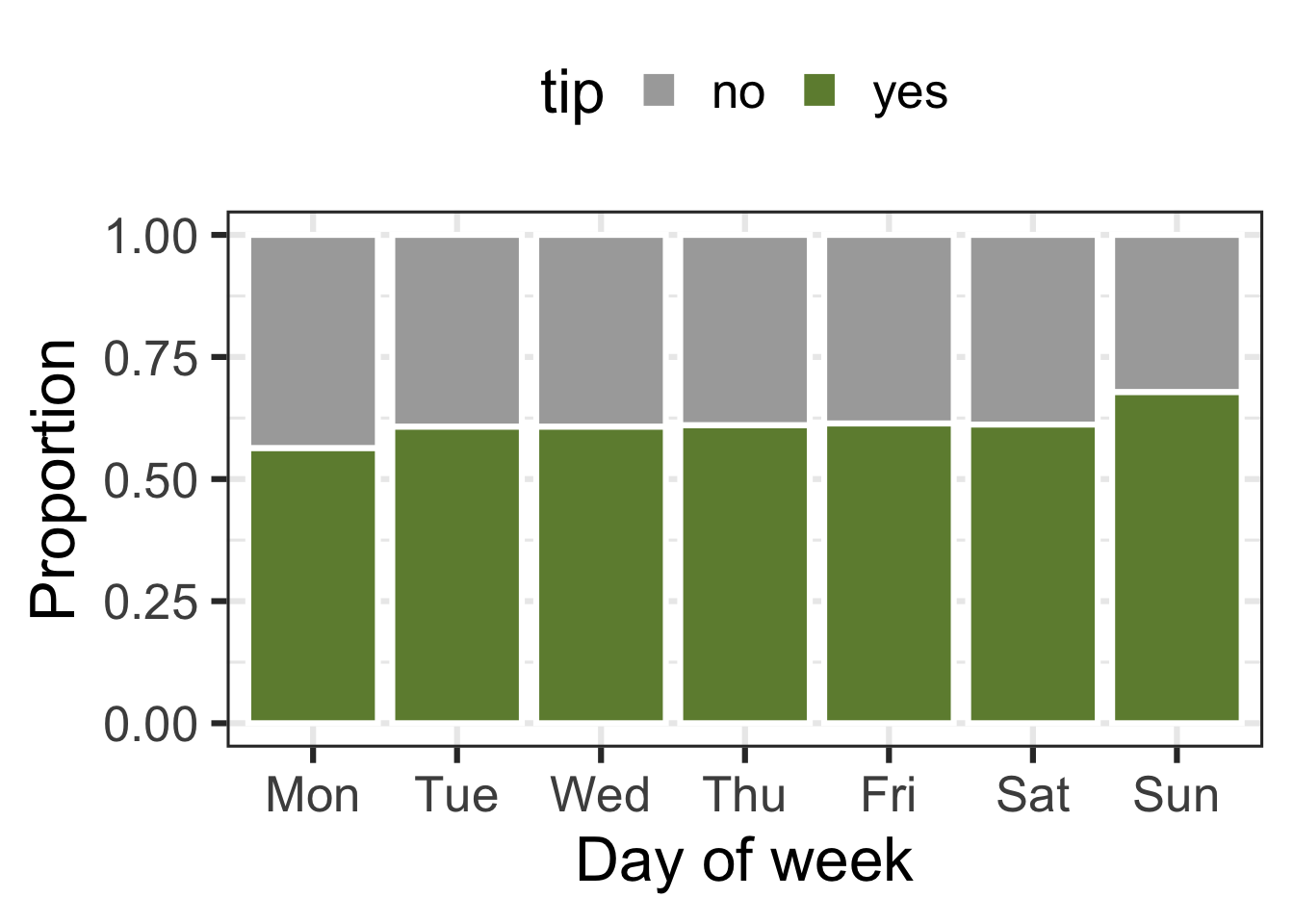
tip and dow
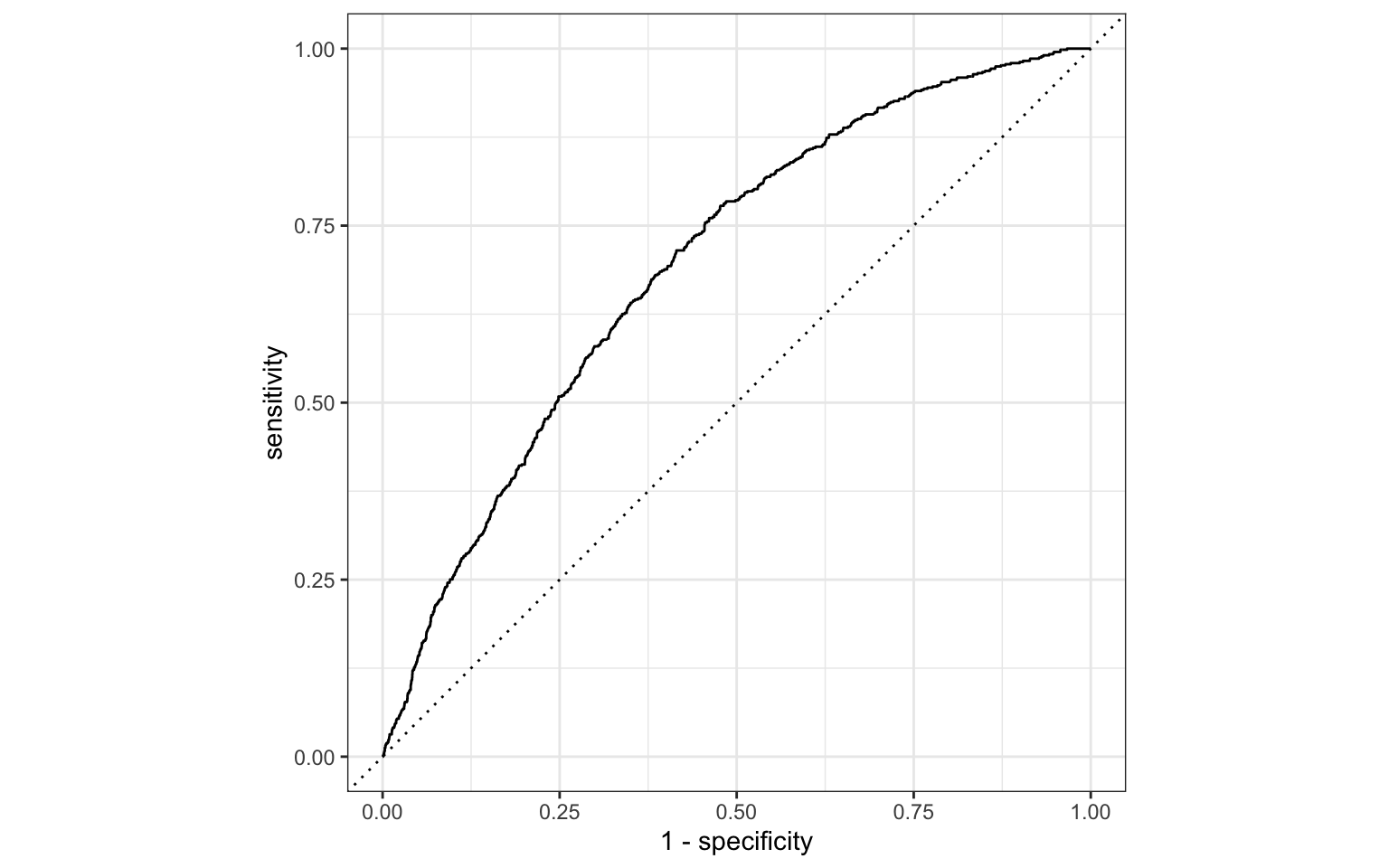
ROC curve
The receiver operating characteristic (ROC) curve allows to assess the model performance across a range of thresholds.
Participate 📱💻
Which of the following best describes the area annotated on the ROC curve?

- Where all positives classified as positive, all negatives classified as negative
- Where true positive rate = false positive rate
- Where all positives classified as negative, all negatives classified as positive
Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.