Web scraping
many pages
Lecture 14
October 9, 2025
While you wait: Participate 📱💻
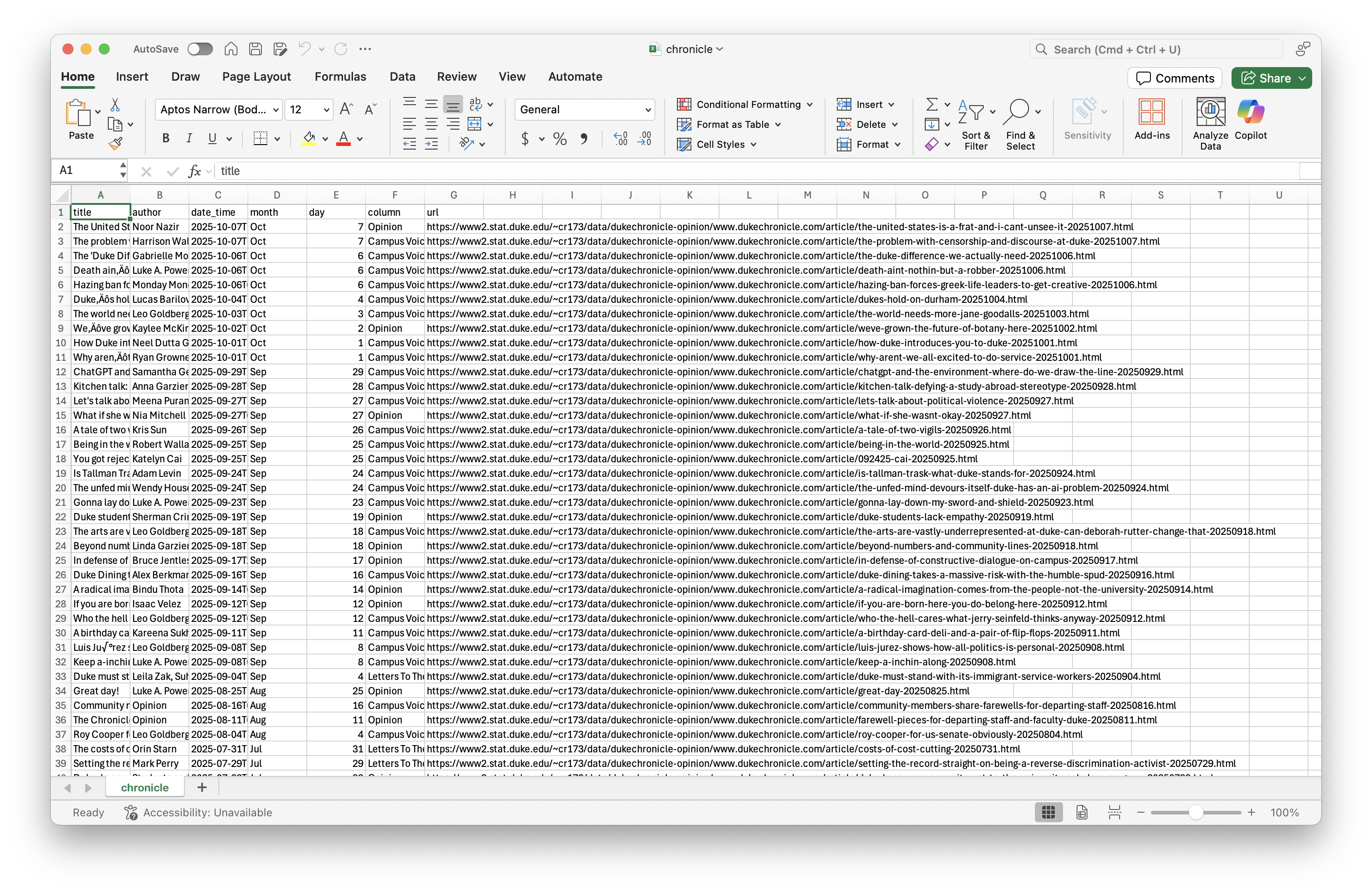
The following code in chronicle-scrape.R extracts titles of an opinion article from The Chronicle website:
Which of the following needs to change to extract column titles instead?
- Change the URL in
read_html() - Change the function
html_elements()tohtml_element() - Change the CSS selector
.space-y-4 .font-extraboldto.space-y-4 .text-brand - Change the function
html_text()tohtml_attr()

Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
Goal
- Scrape data and organize it in a tidy format in R
- Perform light text parsing to clean data
- Summarize and visualze the data
Participate 📱💻
Put the folllowing tasks in order to scrape data from a website:
- Use the SelectorGadget identify tags for elements you want to grab
- Use
read_html()to read the page’s source code into R - Use other functions from the rvest package to parse the elements you’re interested in
- Put the components together in a data frame (a tibble) and analyze it like you analyze any other data
Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.