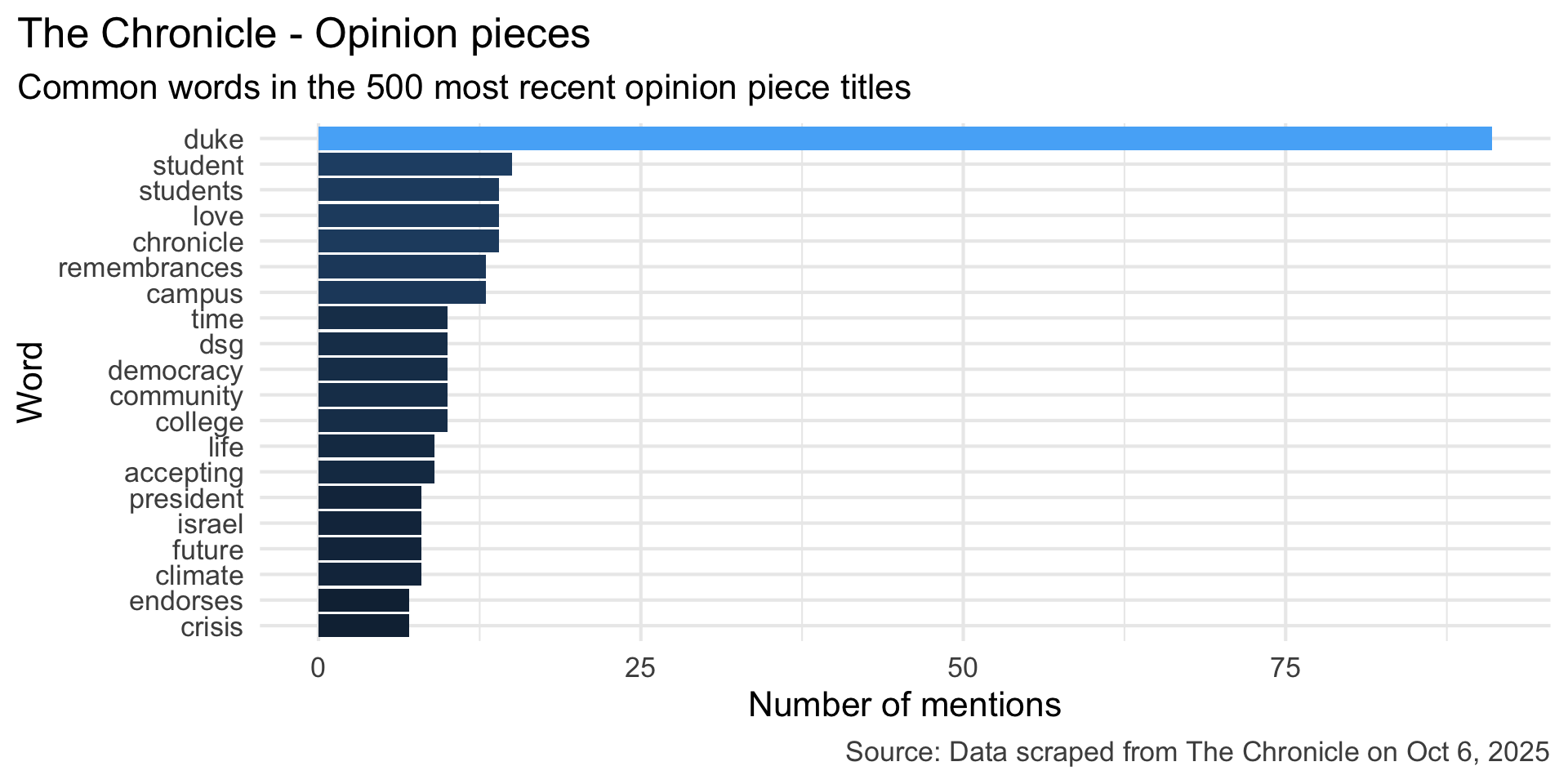
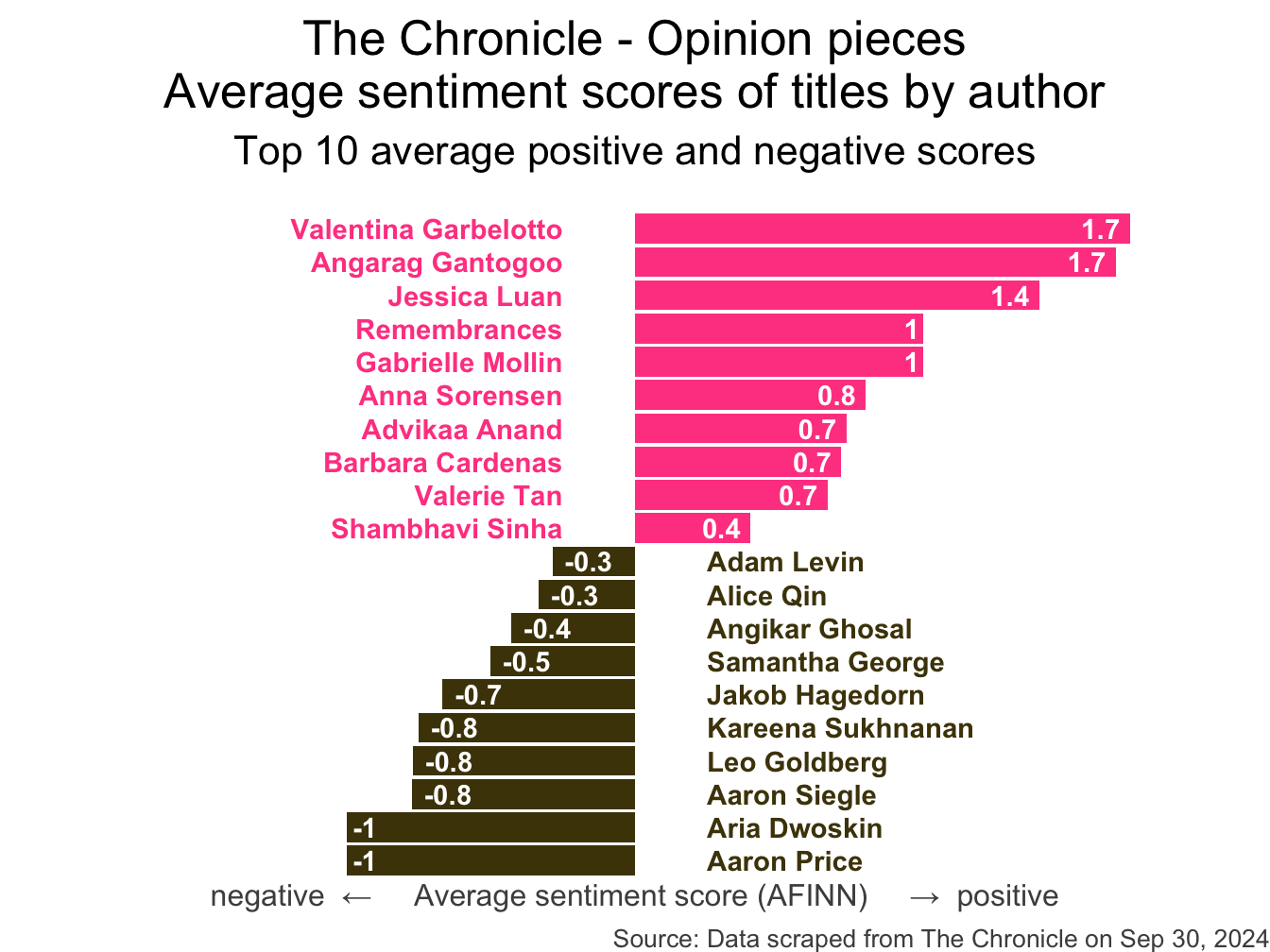
stop_words <- read_csv("data/stop-words.csv")
chronicle |>
tidytext::unnest_tokens(word, title) |>
mutate(word = str_replace_all(word, "’", "'")) |>
anti_join(stop_words) |>
count(word, sort = TRUE) |>
filter(word != "duke's") |>
slice_head(n = 20) |>
mutate(word = fct_reorder(word, n)) |>
ggplot(aes(y = word, x = n, fill = log(n))) +
geom_col(show.legend = FALSE) +
theme_minimal(base_size = 16) +
labs(
x = "Number of mentions",
y = "Word",
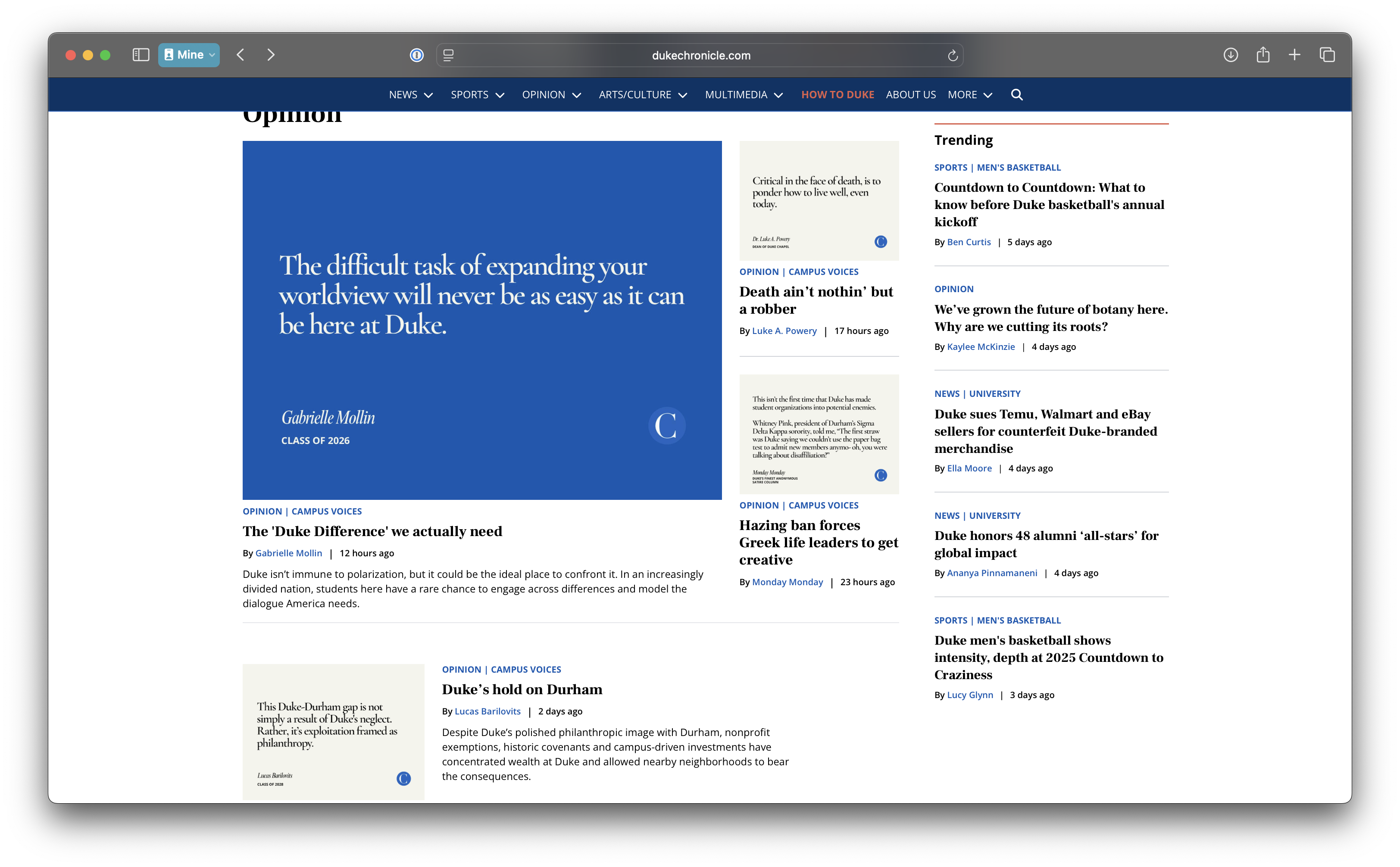
title = "The Chronicle - Opinion pieces",
subtitle = "Common words in the 500 most recent opinion piece titles",
caption = "Source: Data scraped from The Chronicle on Oct 6, 2025"
) +
theme(
plot.title.position = "plot",
plot.caption = element_text(color = "gray30")
)Web scraping
a single page
Lecture 12
October 7, 2025
While you wait: Participate 📱💻
Guess: What is this plot about?
Then, make sure you have a Chrome browser and the SelectorGadget extension installed.

Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
Participate 📱💻
How often do you read The Chronicle?
Scan the QR code or go to app.wooclap.com/sta199. Log in with your Duke NetID.
Analyzing The Chronicle
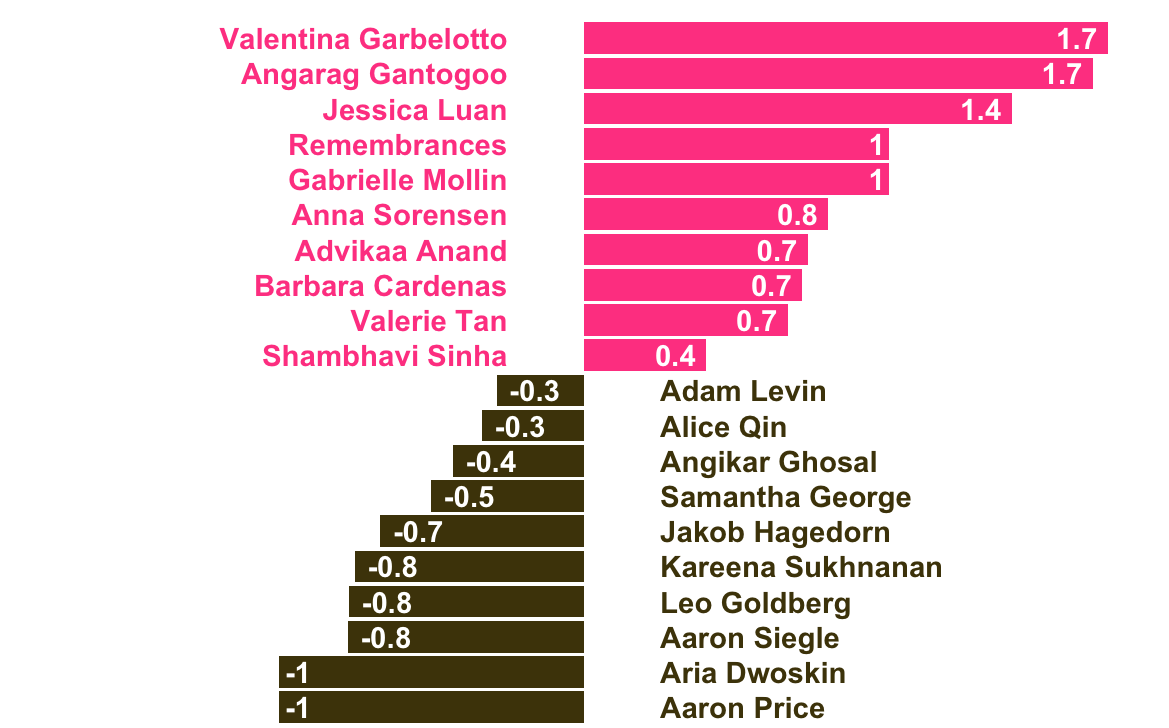
Analyzing The Chronicle
Where is the data coming from?
Where is the data coming from?
# A tibble: 500 × 7
title author date_time month day column url
<chr> <chr> <dttm> <chr> <dbl> <chr> <chr>
1 The United Sta… Noor … 2025-10-07 10:00:00 Oct 7 Opini… http…
2 The problem wi… Harri… 2025-10-07 10:00:00 Oct 7 Campu… http…
3 The 'Duke Diff… Gabri… 2025-10-06 14:30:00 Oct 6 Campu… http…
4 Death ain’t no… Luke … 2025-10-06 10:00:00 Oct 6 Campu… http…
5 Hazing ban for… Monda… 2025-10-06 04:00:00 Oct 6 Campu… http…
6 Duke’s hold on… Lucas… 2025-10-04 10:00:00 Oct 4 Campu… http…
7 The world need… Leo G… 2025-10-03 10:00:00 Oct 3 Campu… http…
8 We’ve grown th… Kayle… 2025-10-02 14:00:00 Oct 2 Opini… http…
9 How Duke intro… Neel … 2025-10-01 10:00:00 Oct 1 Campu… http…
10 Why aren’t we … Ryan … 2025-10-01 10:00:00 Oct 1 Campu… http…
# ℹ 490 more rowsrvest
- The rvest package makes basic processing and manipulation of HTML data straight forward
- It’s designed to work with pipelines built with
|> - rvest.tidyverse.org

SelectorGadget
SelectorGadget (selectorgadget.com) is a javascript based tool that helps you interactively build an appropriate CSS selector for the content you are interested in.
Goal
- Scrape data and organize it in a tidy format in R
- Perform light text parsing to clean data
- Summarize and visualze the data