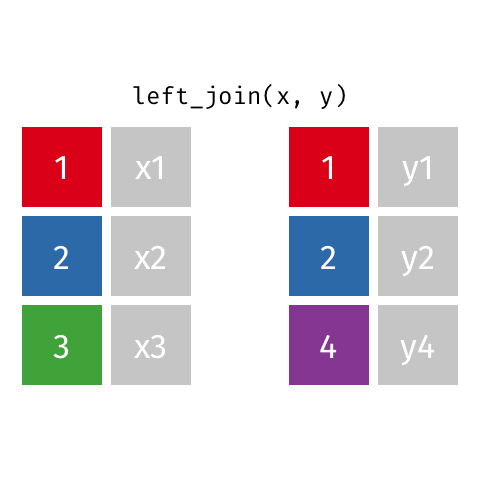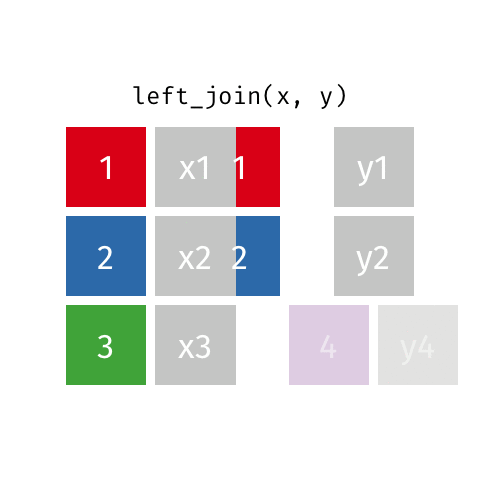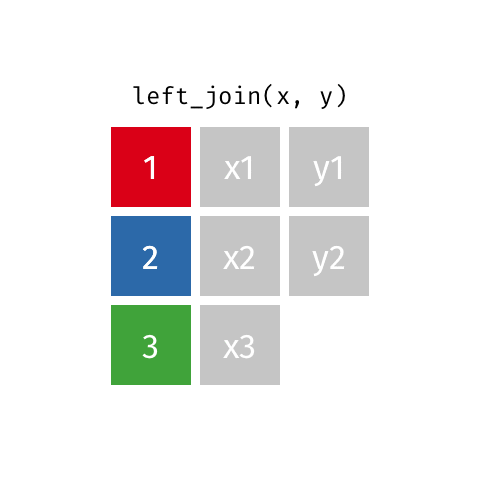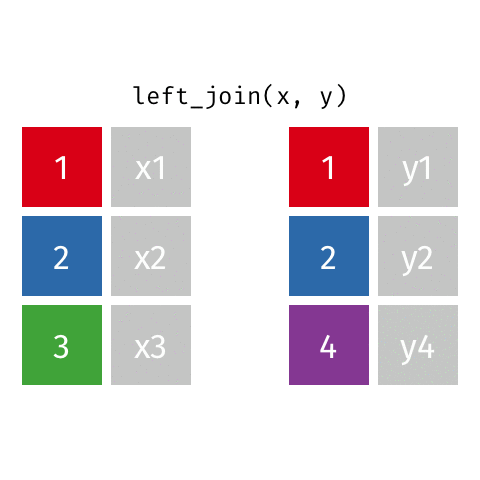
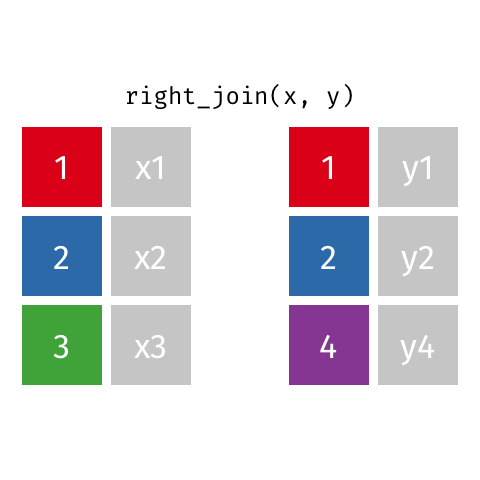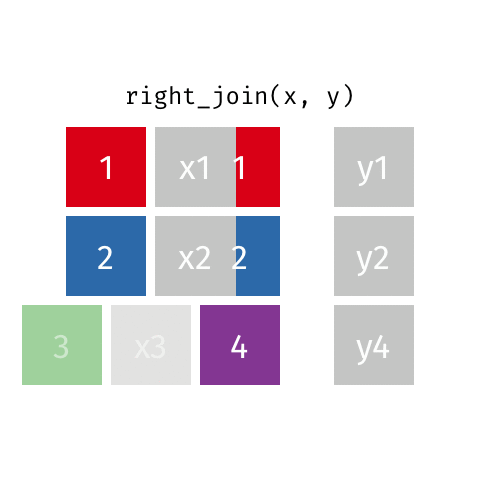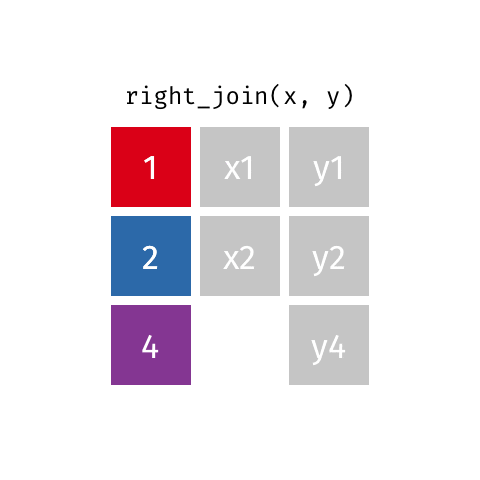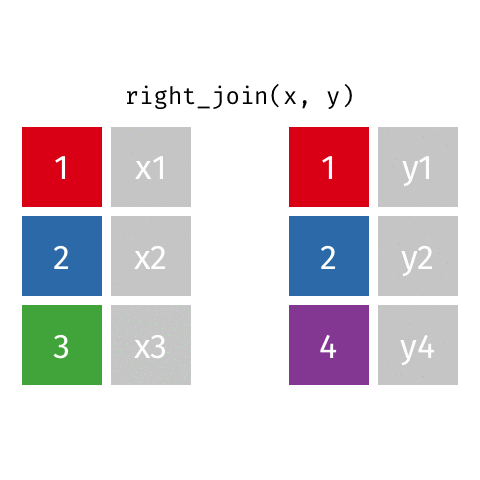
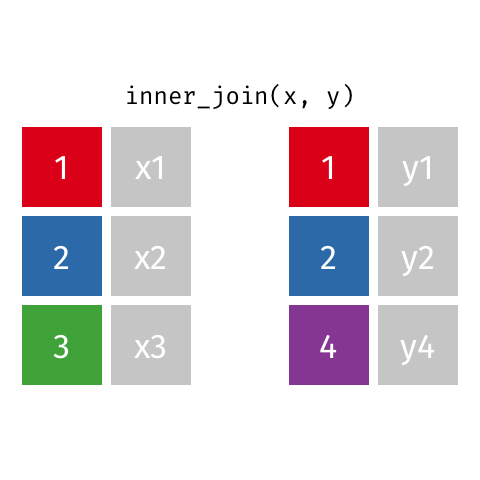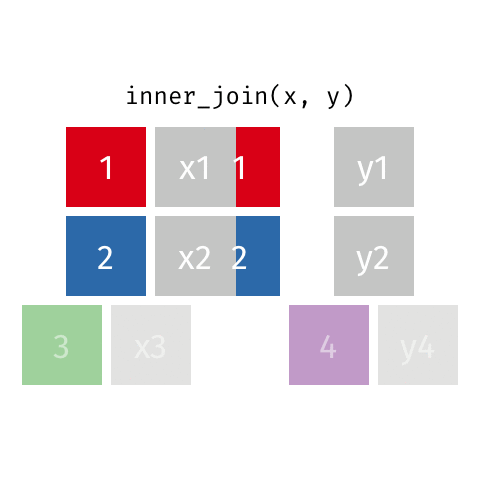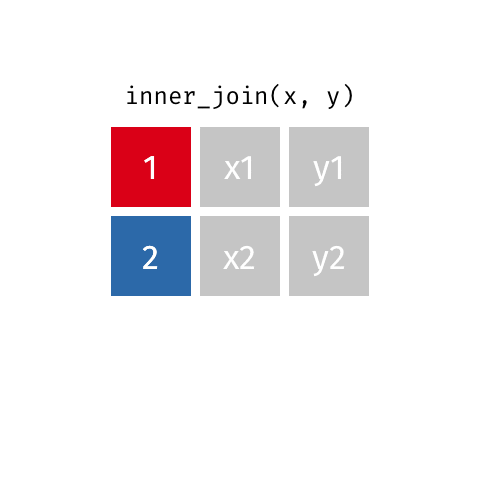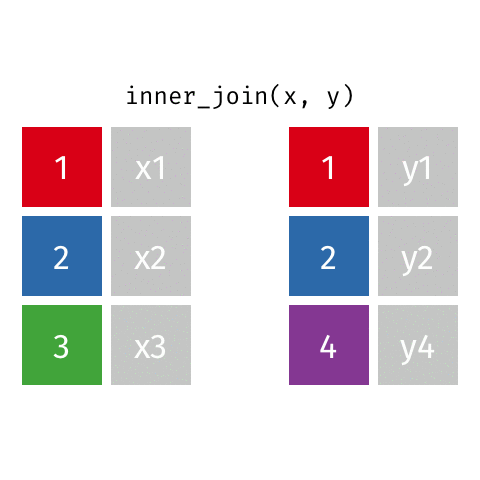
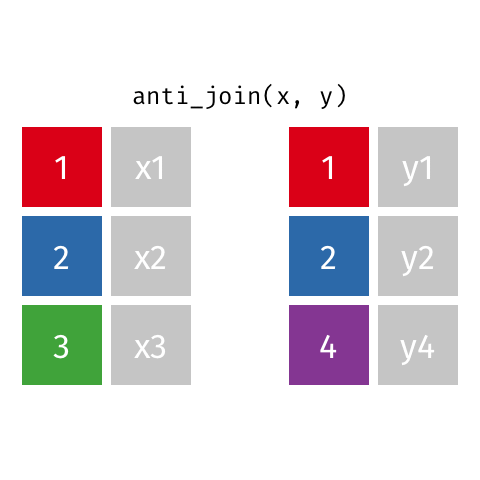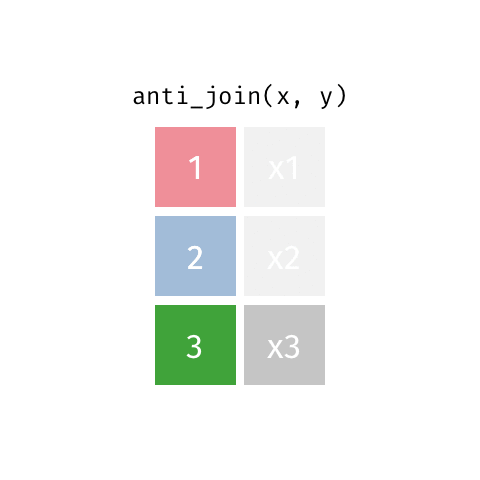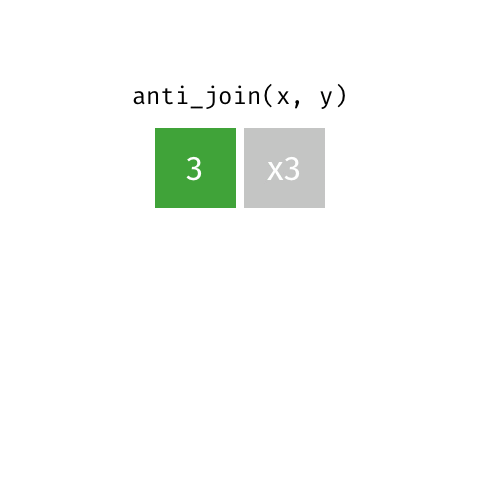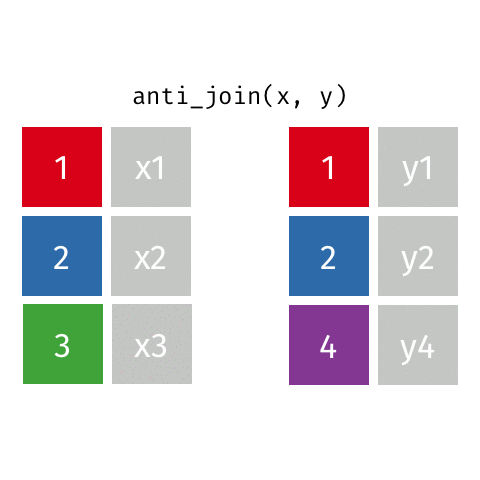
statsci_longer# A tibble: 17 × 3
degree_type year n
<chr> <dbl> <dbl>
1 AB2 2011 0
2 AB2 2012 1
3 AB2 2013 0
4 AB2 2014 0
5 AB2 2015 4
6 AB2 2016 4
7 AB2 2017 1
8 AB2 2018 0
9 AB2 2019 0
10 AB2 2020 1
11 AB2 2021 2
12 AB2 2022 0
13 AB2 2023 3
14 AB2 2024 1
15 AB2 2025 0
16 AB 2011 2
17 AB 2012 2