Introduction
This lab is a deep dive into group_by()!
Make sure to upload your completed lab to Gradescope by the end of your lab session and commit and push your final version to GitHub.
Getting started
To get started, follow the instructions below.
- Go to https://cmgr.oit.duke.edu/containers and login with your Duke NetID and Password.
- Click
STA199under My reservations to log into your container. You should now see the RStudio environment. - Go to the course organization at github.com/sta199-f25 organization on GitHub. Click on the repo with the prefix lab-2. It contains the starter documents you need to complete the homework.
- Click on the green CODE button, select Use SSH. Click on the clipboard icon to copy the repo URL.
- In RStudio, go to File ➛ New Project ➛Version Control ➛ Git.
- Copy and paste the URL of your assignment repo into the dialog box Repository URL. Again, please make sure to have SSH highlighted under Clone when you copy the address.
- Click Create Project, and the files from your GitHub repo will be displayed in the Files pane in RStudio.
Then, click lab-2.qmd to open the template Quarto file and update the authors field to add your name first (first and last) and then your teammates’ names (first and last). Render the document. If you get a popup window error, click “Try again”. Examine the rendered document and make sure your name is updated in the document. Commit and push your changes with a meaningful commit message and push to GitHub.
Guidelines
Code
Code should follow the tidyverse style. Particularly,
- there should be spaces before and line breaks after each
+when building aggplot, - there should also be spaces before and line breaks after each
|>in a data transformation pipeline, - code should be properly indented,
- there should be spaces around
=signs and spaces after commas.
Additionally, all code should be visible in the PDF output, i.e., should not run off the page on the PDF. Long lines that run off the page should be split across multiple lines with line breaks.1
Plots
- Plots should have an informative title and, if needed, also a subtitle.
- Axes and legends should be labeled with both the variable name and its units (if applicable).
- Careful consideration should be given to aesthetic choices.
Workflow
Continuing to develop a sound workflow for reproducible data analysis is important as you complete the lab and other assignments in this course.
- You should have at least 3 commits with meaningful commit messages by the end of the assignment.
- Final versions of both your
.qmdfile and the rendered PDF should be pushed to GitHub.
Packages
In this lab we will work with the tidyverse package.
-
Run the code cell by clicking on the green triangle (play) button for the code cell labeled
load-packages. This loads the package to make its features (the functions and datasets in it) be accessible from your Console. - Then, render the document which loads this package to make its features (the functions and datasets in it) be available for other code cells in your Quarto document.
Questions
For each part of each question below, copy and paste the code cell(s) provided into your Quarto document. Run and analyze the output. Then, answer the questions.
Question 1
Grouping by one variable.
For this question, you will work with the following dataset called df_1. The tibble() function creates the data frame (the tibble object) df_1 with two variables: member and hours. The following code is already included in your lab document.
- What does the following pipeline do? Run it and analyze the result and articulate in words what
arrange()does.
df_1 |>
arrange(member)- What does the following pipeline do? Run it and analyze the result and articulate in words what
group_by()does.
df_1 |>
group_by(member)Render, commit, and push your changes to GitHub with the commit message “Added answer for Q1, parts a and b”.
Make sure to commit and push all changed files so that your Git pane is empty afterward.
- Run the following code cell and analyze the result.
- How many rows does the output have?
- How many columns does the output have?
- Is the output grouped? If so, how many groups does it have?
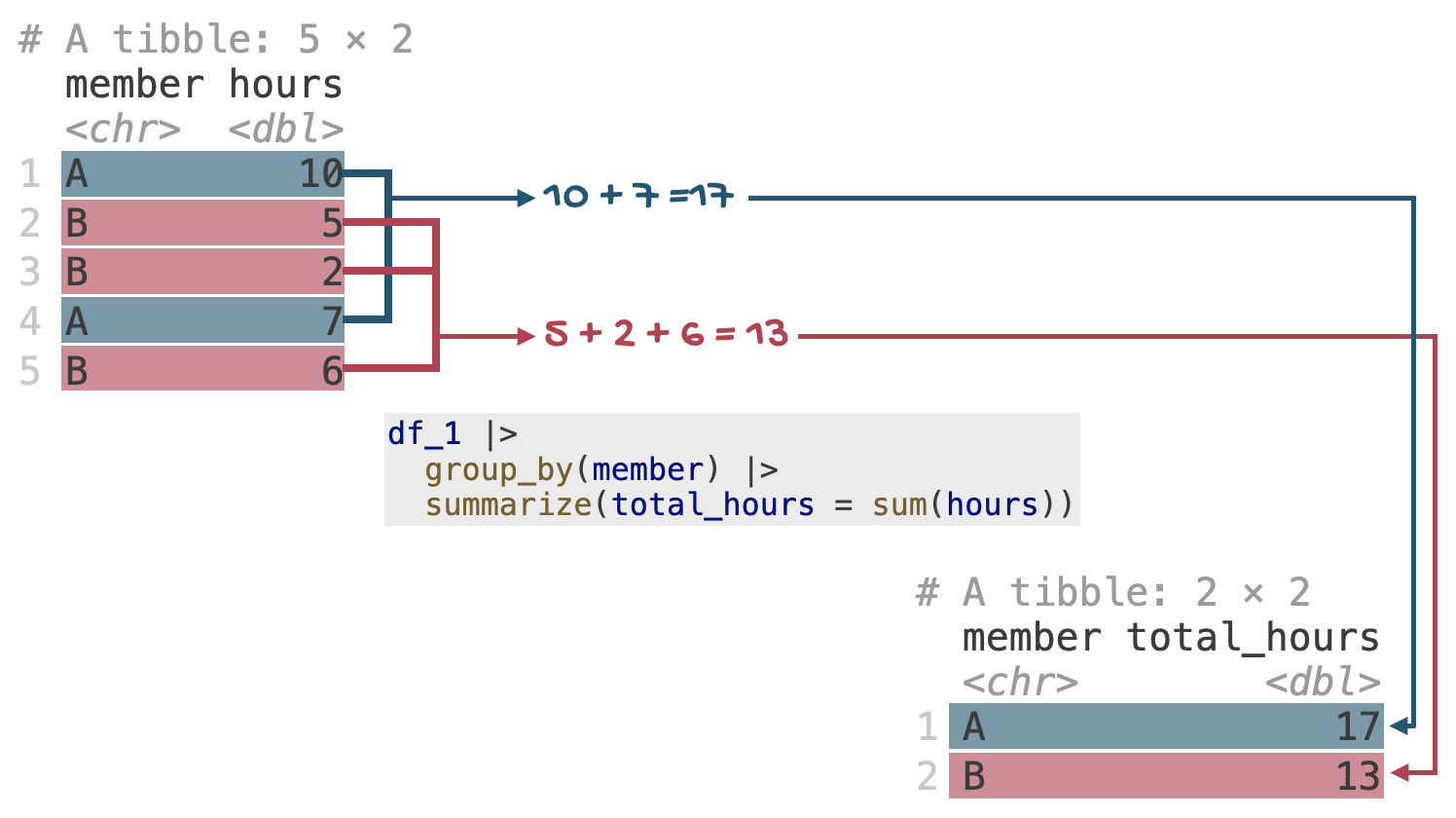
group_by() does- Run the following code cell and analyze the result.
- How many rows does the output have?
- How many columns does the output have?
- Is the output grouped? If so, how many groups does it have?
Render, commit, and push your changes to GitHub with the commit message “Finished Q1”.
Make sure to commit and push all changed files so that your Git pane is empty afterward.
Question 2
Grouping by two variables.
For this question, you will work with the following dataset called df_2. The tibble() function creates the data frame (the tibble object) df_2 with three variables: shift, member and hours. The following code is already included in your lab document.
How many levels does
memberhave? How many levels doesshifthave? How many possible combinations are there of the levels ofmemberandshift?-
Run the following code cell and analyze the result.
- How many rows does the output have?
- How many columns does the output have?
- Is the output grouped? If so, how many groups does it have?
- What does the message mean?
- Run the following code cell and analyze the result.
- How many rows does the output have?
- How many columns does the output have?
- Is the output grouped? If so, how many groups does it have?
- In the following code cell, we add one more step to the data pipelines from the previous two parts. The new step uses
slice_head(n = 1), which is designed to give the first row of the output. Run each and analyze the result. You will notice the results are different. Why?
# pipeline from part b + slice_head()
df_2 |>
group_by(shift, member) |>
summarize(mean_hours = mean(hours)) |>
slice_head(n = 1)
# pipeline from part c + slice_head()
df_2 |>
group_by(shift, member) |>
summarize(mean_hours = mean(hours), .groups = "drop") |>
slice_head(n = 1)- Run the following code cell and analyze the result.
- How many rows does the output have?
- How many columns does the output have?
- Is the output grouped? If so, how many groups does it have?
- Articulate the difference between
summarize()andmutate().
Render, commit, and push your changes to GitHub with a meaningful commit message.
Wrap-up
Before you wrap up the assignment, make sure that you render, commit, and push one final time so that the final versions of both your .qmd file and the rendered PDF are pushed to GitHub and your Git pane is empty. We will be checking these to make sure you have been practicing how to commit and push changes.
Submission
Submit your PDF document to Gradescope by the end of the lab to be considered “on time”:
- Go to http://www.gradescope.com and click Log in in the top right corner.
- Click School Credentials \(\rightarrow\) Duke NetID and log in using your NetID credentials.
- Click on your STA 199 course.
- Click on the assignment, and you’ll be prompted to submit it.
- Mark all the pages associated with question. All the pages of your lab should be associated with at least one question (i.e., should be “checked”).
Make sure you have:
- attempted all questions
- rendered your Quarto document
- committed and pushed everything to your GitHub repository such that the Git pane in RStudio is empty
- uploaded your PDF to Gradescope
Grading and feedback
- This lab is worth 30 points:
- 10 points for being in lab and turning in something – no partial credit for this part.
- 20 points for:
- answering the questions correctly – there is partial credit for this part.
- following the workflow – there is partial credit for this part.
- The workflow points are for:
- committing at least three times as you work through your lab,
- having your final version of
.qmdand.pdffiles in your GitHub repository, and - overall organization.
- You’ll receive feedback on your lab on Gradescope within a week.
Good luck, and have fun with it!
Footnotes
Remember, haikus not novellas when writing code!↩︎